Note
Go to the end to download the full example code.
Multiple-kernel ridge fit from fixed hyper-parameters¶
This example demonstrates how to fit a multiple-kernel ridge model with fixed hyper-parameters. Here are three different usecases:
If the kernel weights hyper-parameters are known and identical across targets, the kernels can be scaled and summed, and a simple KernelRidgeCV can be used to fit the model.
If the kernel weights hyper-parameters are unknown and different across targets, a MultipleKernelRidgeCV can be use to search the best hyper-parameters per target.
If the kernel weights hyper-parameters are known and different across targets, a WeightedKernelRidge model can be used to fit the ridge models on each target independently.
This method can be used for example in the following workflow:
fit a MultipleKernelRidgeCV to learn the kernel weights hyper-parameter,
save the hyper-parameters, but not the ridge weights to save disk space,
fit a WeightedKernelRidge from the saved hyper-parameters, for further use of the model (prediction, interpretation, etc.).
import numpy as np
from himalaya.backend import set_backend
from himalaya.kernel_ridge import WeightedKernelRidge
from himalaya.kernel_ridge import Kernelizer
from himalaya.kernel_ridge import ColumnKernelizer
from himalaya.utils import generate_multikernel_dataset
from sklearn.pipeline import make_pipeline
from sklearn import set_config
set_config(display='diagram')
In this example, we use the torch_cuda backend (GPU).
backend = set_backend("torch_cuda", on_error="warn")
/home/runner/work/himalaya/himalaya/himalaya/backend/_utils.py:66: UserWarning: Setting backend to torch_cuda failed: PyTorch with CUDA is not available..Falling back to numpy backend.
warnings.warn(f"Setting backend to {backend} failed: {str(error)}."
Generate a random dataset¶
X_train : array of shape (n_samples_train, n_features)
X_test : array of shape (n_samples_test, n_features)
Y_train : array of shape (n_samples_train, n_targets)
Y_test : array of shape (n_samples_test, n_targets)
(X_train, X_test, Y_train, Y_test, kernel_weights,
n_features_list) = generate_multikernel_dataset(n_kernels=4, n_targets=500,
n_samples_train=1000,
n_samples_test=400,
random_state=42)
Prepare the pipeline¶
# Find the start and end of each feature space X in Xs
start_and_end = np.concatenate([[0], np.cumsum(n_features_list)])
slices = [
slice(start, end)
for start, end in zip(start_and_end[:-1], start_and_end[1:])
]
# Create a different ``Kernelizer`` for each feature space.
kernelizers = [("space %d" % ii, Kernelizer(), slice_)
for ii, slice_ in enumerate(slices)]
column_kernelizer = ColumnKernelizer(kernelizers)
Define the weighted kernel ridge model¶
Here we use the ground truth kernel weights for each target (deltas), but it can be typically used with deltas obtained from a MultipleKernelRidgeCV fit.
deltas = backend.log(backend.asarray(kernel_weights.T))
model_1 = WeightedKernelRidge(alpha=1, deltas=deltas, kernels="precomputed")
pipe_1 = make_pipeline(column_kernelizer, model_1)
# Fit the model on all targets
pipe_1.fit(X_train, Y_train)
compute test score
test_scores_1 = pipe_1.score(X_test, Y_test)
test_scores_1 = backend.to_numpy(test_scores_1)
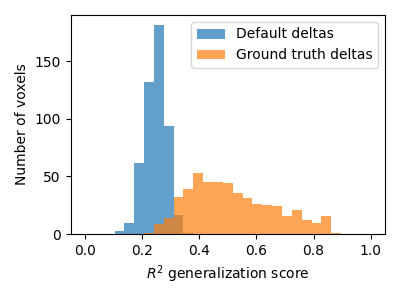
We can compare this model to a baseline model where the kernel weights are all equal and not learnt.
model_2 = WeightedKernelRidge(alpha=1, deltas="zeros", kernels="precomputed")
pipe_2 = make_pipeline(column_kernelizer, model_2)
# Fit the model on all targets
pipe_2.fit(X_train, Y_train)
compute test score
test_scores_2 = pipe_2.score(X_test, Y_test)
test_scores_2 = backend.to_numpy(test_scores_2)
Compare the predictions on a test set¶
import matplotlib.pyplot as plt
plt.figure(figsize=(4, 3))
plt.hist(test_scores_2, np.linspace(0, 1, 30), alpha=0.7,
label="Default deltas")
plt.hist(test_scores_1, np.linspace(0, 1, 30), alpha=0.7,
label="Ground truth deltas")
plt.xlabel("$R^2$ generalization score")
plt.ylabel("Number of voxels")
plt.legend()
plt.tight_layout()
plt.show()
Total running time of the script: (0 minutes 3.586 seconds)