Publications
For a complete list of publications, visit our Google Scholar page.
2026
Bilingual language processing relies on shared semantic representations that are modulated by each language (Chen et al., PNAS, 2026)
We performed fMRI scans of English-Chinese bilinguals while they read natural narratives in each language. Semantic representations are largely shared between languages, but finer-grained differences systematically alter how the same meaning is represented. Semantic brain representations in bilinguals are shared across languages but modulated by each language.
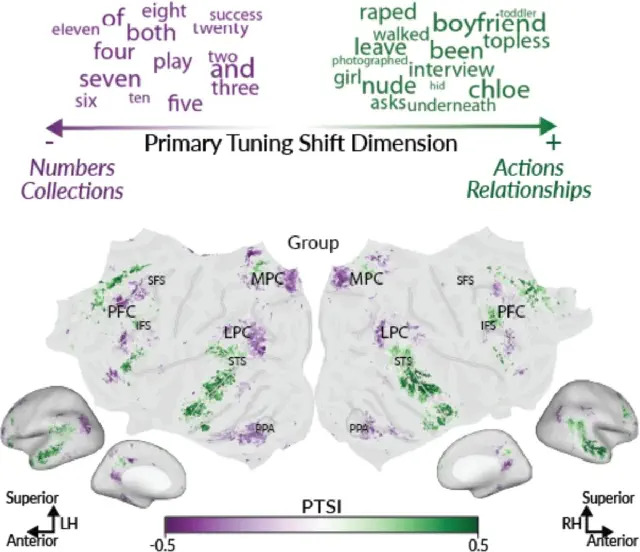
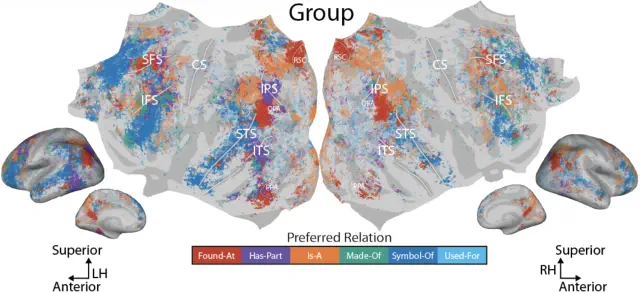
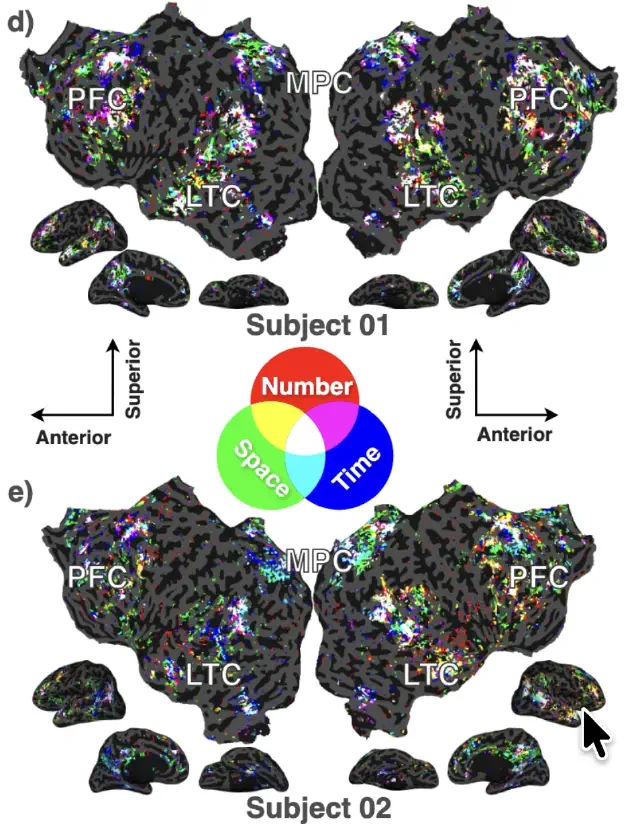
Representations of semantic relations in the human cerebral cortex (Chen et al., bioRxiv preprint, 2026)
Little is known about how semantic relations between concepts are encoded in the human brain. We collected fMRI data while participants answered relation-verification questions about over 1000 concept pairs (e.g., bicycle has-part wheel), then fit voxelwise encoding models to identify where and how each relation is represented. Semantic relations and concepts are encoded in the same bilateral temporal, parietal, and prefrontal regions; most voxels are preferentially selective for a single relation, and the cortical organization of preferred relations is consistent across participants.
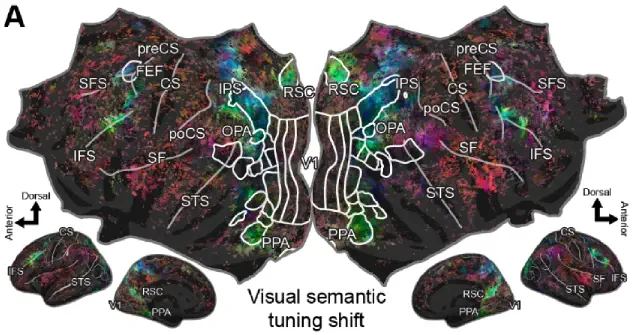
Visual semantic tuning across the cortex shifts between tasks (Zhang and Gallant, bioRxiv preprint, 2026)
Attention modulates brain representations to prioritize task-relevant information, but how visual semantic tuning shifts between naturalistic tasks is not well understood. We used voxelwise encoding models to compare visual semantic representations across the cortex in participants who watched movies versus participants who navigated a virtual city. Visual semantic tuning differs substantially between tasks—during navigation, tuning shifts increase the representation of task-relevant objects, with the strongest shifts in place-selective and visual attention regions and the weakest in human-selective regions.
2025
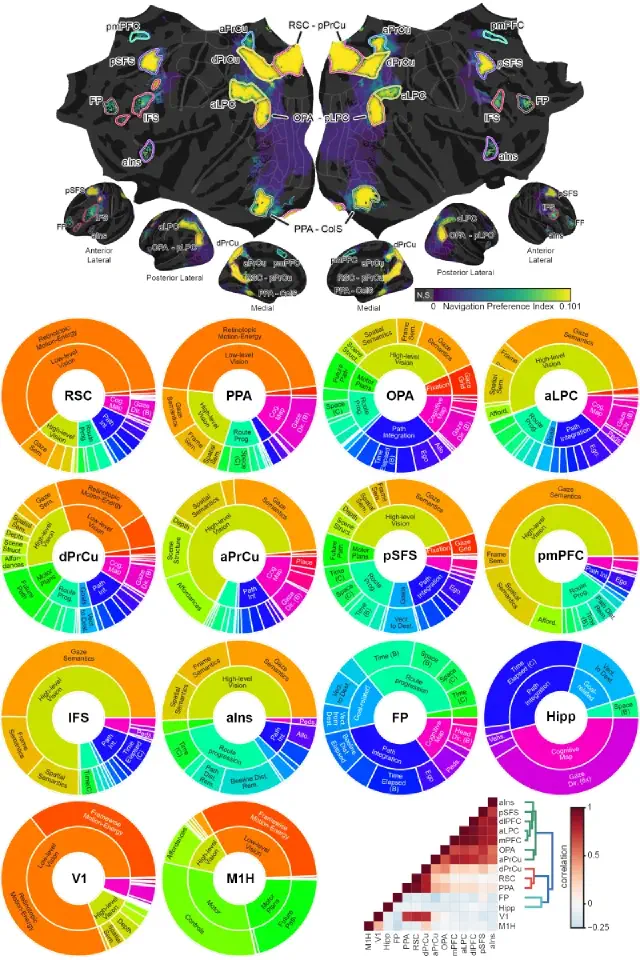
A map of the cortical functional network mediating naturalistic navigation (Zhang, Meschke, Gallant, bioRxiv preprint, 2025)
Natural navigation requires close coordination of perception, planning, and motor actions. We used fMRI to record brain activity while participants performed a taxi driver task in VR, then fit high-dimensional voxelwise encoding models to the data. Navigation is supported by a network of 11 functionally distinct cortical regions that transform perceptual inputs through decision-making processes to produce action outputs.
Disentangling Superpositions: Interpretable Brain Encoding Model with Sparse Concept Atoms (Zeng and Gallant, NeurIPS, 2025)
Dense ANN word embeddings entangle multiple concepts in each feature, making it difficult to interpret encoding model maps. We use a Sparse Concept Encoding Model to produce a feature space where each dimension corresponds to an interpretable concept. The resulting model matches the prediction performance of dense models while substantially enhancing interpretability.
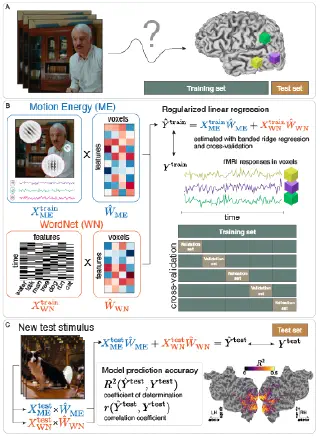
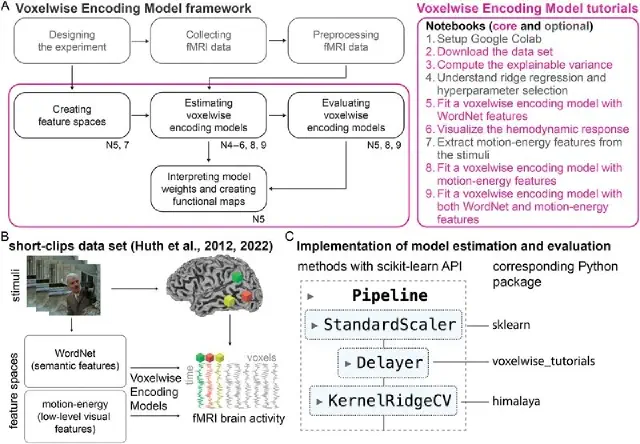
Encoding models in functional magnetic resonance imaging: the Voxelwise Encoding Model framework (Visconti di Oleggio Castello, Deniz, et al., PsyArXiv preprint, 2025)
This review paper provides the first comprehensive guide to the Voxelwise Encoding Model (VEM) framework. The VEM framework is a framework for fitting encoding models to fMRI data. This framework is currently the most sensitive and powerful approach available for modeling fMRI data. It can be used to fit dozens of distinct models simultaneously, each model having up to several thousand distinct features. The Voxelwise Encoding Model framework also conforms to all best practices in data science, which maximizes sensitivity, reliability and generalizability of the resulting models.
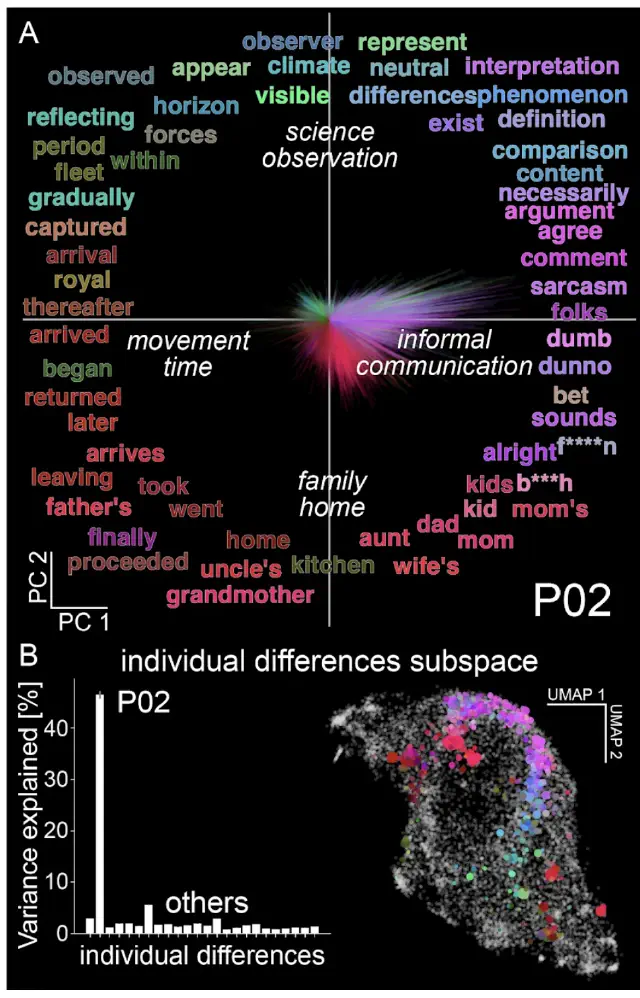
Individual differences shape conceptual representation in the brain (Visconti di Oleggio Castello et al., bioRxiv preprint, 2025)
We developed a new computational framework to measure and interpret individual differences in functional brain maps. We found robust individual differences in conceptual representation that reflect cognitive traits unique to each person. This framework enables new precision neuroscience approaches to the study of complex functional representations.
The Voxelwise Encoding Model framework: A tutorial introduction to fitting encoding models to fMRI data (Dupré la Tour et al., Imaging Neuroscience, 2025)
This tutorial provides practical guidance on using the Voxelwise Encoding Model (VEM) framework for functional brain mapping. It includes hands-on examples with public datasets, code repositories, and interactive notebooks to make this powerful methodology accessible to researchers at all levels.
2024
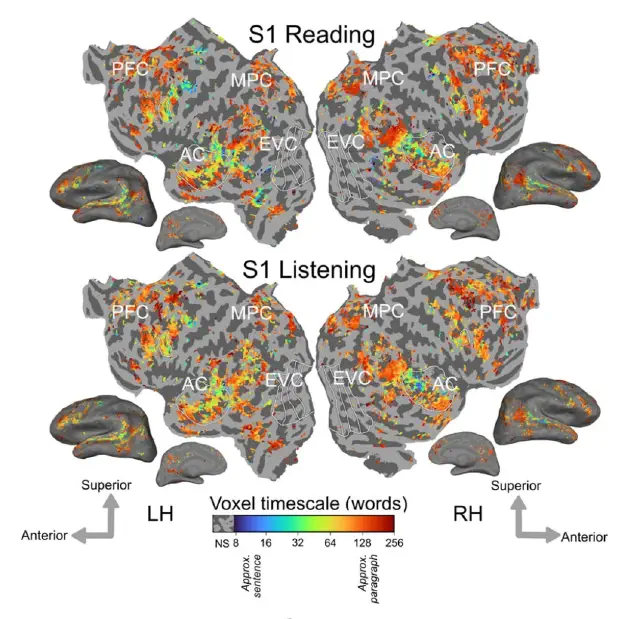
The cortical representation of language timescales is shared between reading and listening (Chen et al., Communications Biology, 2024)
Language comprehension involves integrating low-level sensory inputs into a hierarchy of increasingly high-level features. To recover this hierarchy we mapped the intrinsic timescale of language representation across the cerebral cortex during listening and reading. We find that the timescale of representation is organized similarly for the two modalities.
2023
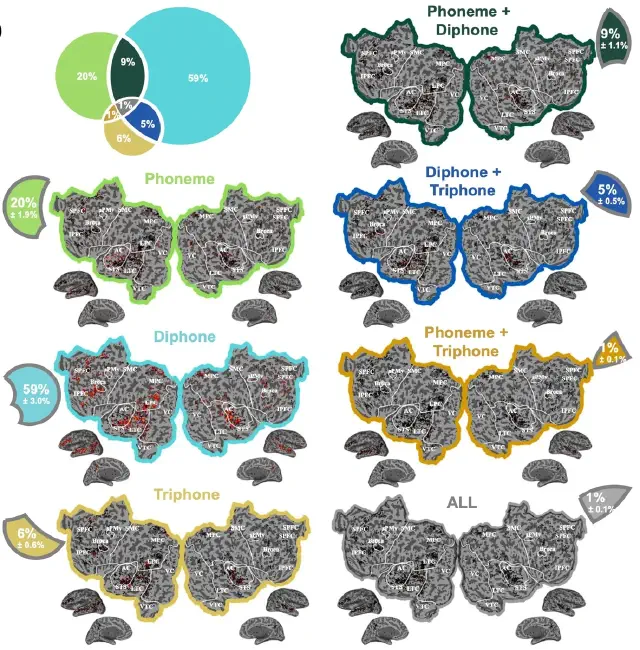
Phonemic segmentation of narrative speech in human cerebral cortex (Gong et al., Nature Communications, 2023)
This fMRI study identifies the brain representation of single phonemes, diphones, and triphones during natural speech. Many regions in and around auditory cortex represent phonemes, and we identify regions where phonemic processing and lexical retrieval are intertwined. (Collaboration with the Theunissen lab at UCB.)
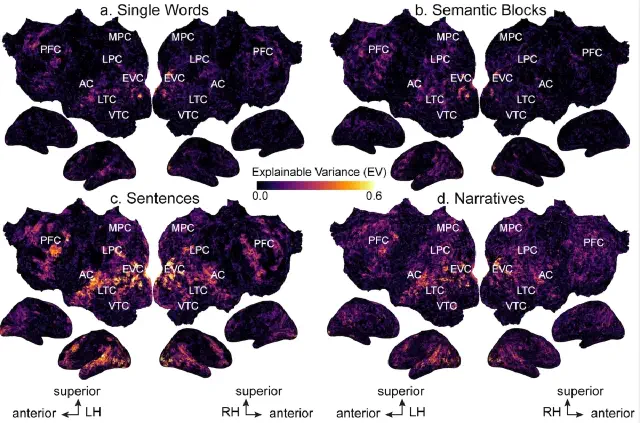
Semantic representations during language comprehension are affected by context (Deniz et al., Journal of Neuroscience, 2023)
Most neuroimaging studies of meaning use isolated words and sentences with little context. We find that increasing context improves the quality of neuroimaging data and changes where and how semantic information is represented in the brain. Findings from studies using out-of-context stimuli may not generalize to natural language used in daily life.
2022
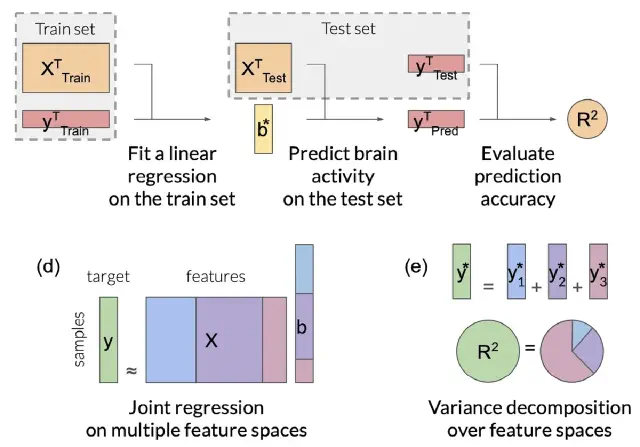
Feature-space selection with banded ridge regression (Dupré la Tour et al., Neuroimage, 2022)
Encoding models identify the information represented in brain recordings, but fitting multiple models simultaneously presents several challenges. This paper describes how banded ridge regression can be used to solve these problems. Furthermore, several methods are proposed to address the computational challenge of fitting banded ridge regressions on large numbers of voxels and feature spaces. All implementations are released in an open-source Python package called Himalaya.
2021
Visual and linguistic semantic representations are aligned at the border of human visual cortex (Popham et al., Nature Neuroscience, 2021)
We examined the spatial organization of visual and amodal semantic functional maps. The pattern of semantic selectivity in these two networks corresponds along the boundary of visual cortex: for categories represented posterior to the boundary, the same categories are represented linguistically on the anterior side. These two networks are smoothly joined to form one contiguous map.
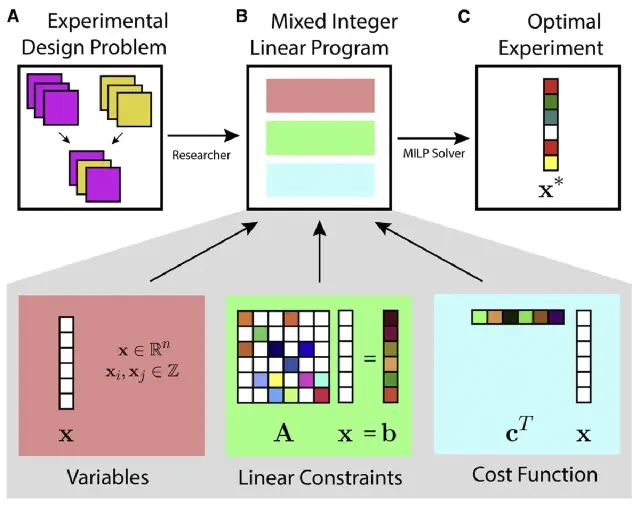
Design of complex neuroscience experiments using mixed-integer linear programming (Slivkoff and Gallant, Neuron, 2021)
This tutorial and primer reviews how mixed integer linear programming can be used to optimize the design of complex experiments using many different variables. The approach is particularly useful when designing complex fMRI experiments--such as question answering studies--that aim to manipulate and probe many dimensions simultaneously.
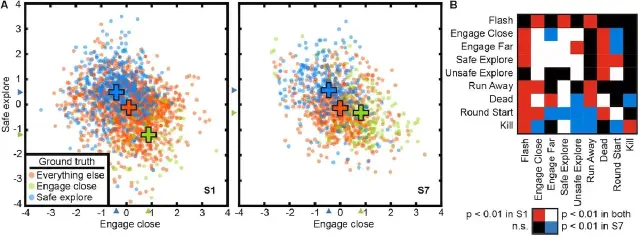
Voxel-based state space modeling recovers task-related cognitive states in naturalistic fMRI experiments (Zhang et al., Front. Neuro., 2021)
We present a voxel-based state space modeling method for recovering task-related state spaces from fMRI data. Applied to a visual attention task and a video game task, each task induces distinct brain states that can be embedded in a low-dimensional state space that reflects task parameters.
2019
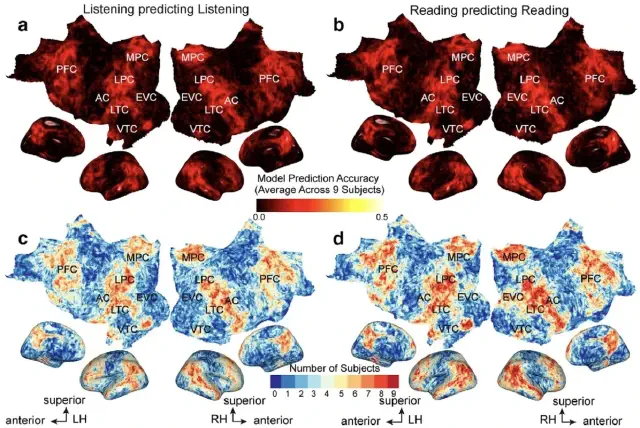
The representation of semantic information across human cerebral cortex during listening versus reading is invariant to stimulus modality (Deniz et al., J. Neurosci., 2019)
We show that although the representation of semantic information in the human brain is quite complex, the semantic representations evoked by listening versus reading are almost identical. The representation of language semantics is independent of the sensory modality through which the semantic information is received.
Voxelwise encoding models with non-spherical multivariate normal priors (Nunez-Elizalde, Huth & Gallant, NeuroImage, 2019)
Ridge regression assumes a spherical Gaussian prior with equal variance for all model parameters, but this is not always appropriate. This paper shows how non-spherical priors via Tikhonov regression can improve encoding models. A key application is banded ridge regression, which assigns a separate regularization parameter to each feature space and provides substantially better prediction accuracy when combining multiple feature spaces.
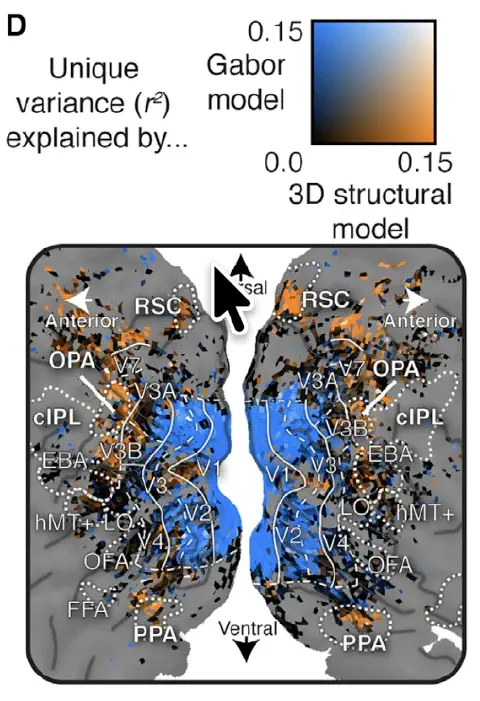
Human scene-selective areas represent 3D configurations of surfaces (Lescroart et al., Neuron, 2019)
It has been argued that scene-selective areas in the human brain represent both the 3D structure of the local visual environment and low-level 2D features that provide cues for 3D structure. To evaluate these hypotheses we developed an encoding model of 3D scene structure and tested it against a model of low-level 2D features. We fit the models to fMRI data recorded while subjects viewed visual scenes. Scene-selective areas represent the distance to and orientation of large surfaces. The most important dimensions of 3D structure are distance and openness.
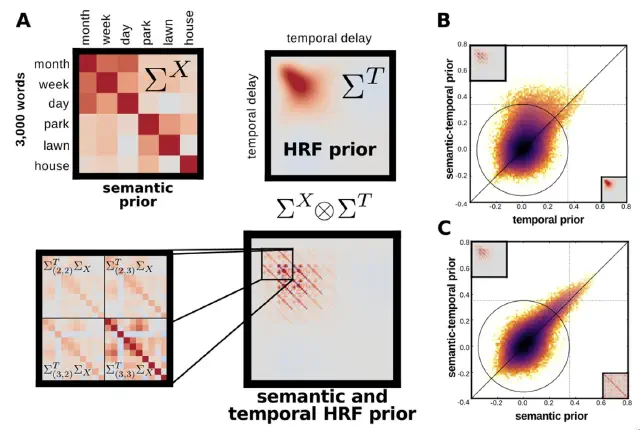
2017
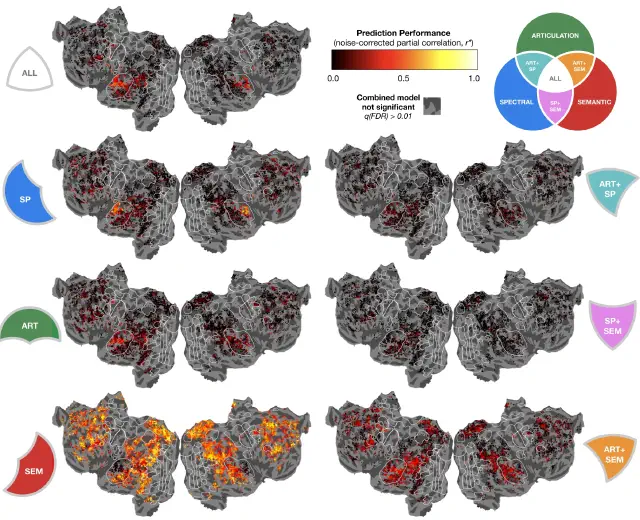
The hierarchical cortical organization of human speech processing (de Heer, Huth, Griffiths, Gallant & Theunissen, J. Neurosci., 2017)
We used voxelwise encoding models and variance partitioning to investigate how the brain transforms speech sounds into meaning. Speech processing involves a cortical hierarchy: spectral features in A1, articulatory features in STG, and semantic features in STS and beyond. Both hemispheres are equally involved, and semantic representations appear surprisingly early in the hierarchy.
Eye movement-invariant representations in the human visual system (Nishimoto, Huth, Bilenko & Gallant, Journal of Vision, 2017)
Visual representations must be robust to eye movements, but the degree of eye movement invariance across the visual hierarchy is not well understood. We used fMRI to compare brain activity while subjects watched natural movies during fixation and free viewing. Responses in ventral temporal areas are largely invariant to eye movements, while early visual areas are strongly affected. These results suggest that the ventral temporal areas maintain a stable representation of the visual world during natural vision.
2016
Decoding the semantic content of natural movies from human brain activity (Huth et al., Frontiers in Systems Neuroscience, 2016)
This paper presents a decoding algorithm, hierarchical logistic regression, that recovers detailed information about the object and action categories present in natural movies from fMRI responses with high accuracy. The framework can also be used to test whether semantic relationships defined in the WordNet taxonomy are represented the same way in the human brain.
Natural speech reveals the semantic maps that tile human cerebral cortex (Huth et al., Nature, 2016)
We collected fMRI while subjects listened to narrative stories and recovered detailed lexical-semantic maps by voxelwise modeling. The semantic system is organized into intricate patterns that are consistent across individuals. Most areas represent information about groups of related concepts, and our semantic atlas shows which concepts are represented in each area.

2015
Fourier power, subjective distance, and object categories all provide plausible models of BOLD responses in scene-selective visual areas (Lescroart, Stansbury & Gallant, Frontiers in Computational Neuroscience, 2015)
It is unclear what specific features the scene-selective areas (PPA, RSC, OPA) represent. We evaluated three classes of features: 2D Fourier power, 3D spatial structure, and abstract categories. The variance explained by the three models is largely shared and each explains little unique variance, so there is currently no strong reason to favor one model over another.
A voxel-wise encoding model for early visual areas decodes mental images of remembered scenes (Naselaris et al., NeuroImage, 2015)
Are low-level visual features encoded during mental imagery of complex scenes? Voxel-wise encoding models were fit to fMRI responses to works of art, then used to decode activity as subjects imagined those same works. Mental images could be accurately identified, with accuracy depending on each voxel's tuning to low-level features. We also demonstrate a proof-of-concept image search guided by mental imagery.
2013
Natural scene statistics account for the representation of scene categories in human visual cortex (Stansbury, Naselaris & Gallant, Neuron, 2013)
Much of human visual cortex appears to be selective for specific categories of natural scenes. However, it is unknown whether this scene selectivity is essentially arbitrary, or rather whether it reflects the statistical structure of natural scenes. This paper uses a machine learning algorithm to discover the intrinsic categorical structure of natural scenes, and then uses fMRI to show that the human brain represents these natural categories.
Attention during natural vision warps semantic representation across the human brain (Çukur et al., Nature Neuroscience, 2013)
The human brain consists of hundreds of distinct functional areas, and each area represents different information about the external and internal world. This study shows that these representations are task-dependent: directing attention toward a particular category of objects warps the semantic representation across much of cortex to expand the representation of attended and related categories.
2012
A continuous semantic space describes the representation of thousands of object and action categories across the human brain (Huth et al., Neuron, 2012)
This study shows how 1,705 distinct object and action categories are mapped systematically across the surface of the cerebral cortex, revealing a continuous semantic space that is represented smoothly across much of visual and non-visual cortex.
System identification, encoding models, and decoding models: a powerful new approach to fMRI research (Gallant, Nishimoto, Naselaris & Wu, in Visual Population Codes, MIT Press, 2012)
Most fMRI experiments employ a deductive approach in which a specific hypothesis governs selection of a narrow range of stimulus and task parameters. This chapter explains an alternative approach called system identification (SI). The goal of SI is to construct an explicit encoding model for each voxel that predicts responses to any arbitrary input. This approach is much more efficient and much more powerful than the conventional approach.
2011
Reconstructing visual experiences from brain activity evoked by natural movies (Nishimoto et al., Current Biology, 2011)
This study uses a novel motion-energy model of human visual cortex to reconstruct movies from brain activity. By measuring fMRI responses while subjects watched natural movies and inverting an encoding model, the authors recovered approximate reconstructions of the movies that subjects had seen.
Encoding and decoding in fMRI (Naselaris et al., NeuroImage, 2011)
This paper provides a general framework to understand the relationship between encoding models of the brain and brain decoding. It also explains in detail one particularly powerful approach to brain decoding based on Bayesian decoding of voxel-wise models.
2009
Bayesian reconstruction of natural images from human brain activity (Naselaris et al., Neuron, 2009)
This paper presents the first successful approach for reconstructing natural images from human brain activity. It provides clear demonstrations of the application of Bayesian decoding of voxel-wise models, and it illustrates the importance of the prior.
2008
Identifying natural images from human brain activity (Kay et al., Nature, 2008)
Functional MRI measures hemodynamic signals that are indirectly coupled to neural activity. Thus, fMRI is an inherently limited method that cannot recover all of the information available in the brain. However, this landmark paper shows that far more information can be recovered from fMRI signals than had been believed previously.
Modeling low-frequency fluctuation and hemodynamic response timecourse in event-related fMRI (Kay et al., Human Brain Mapping, 2008)
Pre-processing is a critical stage of any fMRI study and can dramatically affect data quality. This technical paper describes one approach to pre-processing and modeling fMRI data used in our laboratory circa 2008. It remains valuable for its account of fMRI pre-processing problems, though many aspects of the pipeline have since been superseded.
2007
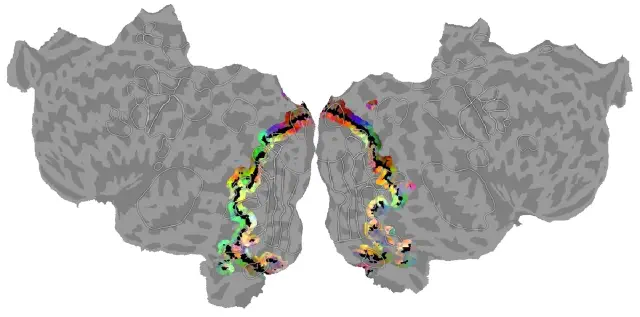
Topographic organization in and near human visual area V4 (Hansen, Kay & Gallant, Journal of Neuroscience, 2007)
Whether human visual area V4 is organized like V4 in non-human primates has long been debated: primate V4 has separate ventral and dorsal components, whereas human studies have argued the two halves are contiguous. This detailed mapping study, including a crucial selective-attention experiment, concludes that human V4 is organized analogously to the primate, with separate ventral and dorsal halves.